Your Benchmark Is the Only One That Matters
Six AI coding agents. One production task. The results reveal a gap that no leaderboard can see.
I've spent years evaluating technology for a living — first in physics labs measuring things at 10⁻¹¹ torr, then in venture doing technical due diligence on blockchain protocols, now advising on AI adoption across enterprise and startup contexts. The through-line has always been the same: the gap between what something claims to do and what it actually does under real conditions is where the interesting information lives.
This is a dispatch about that gap. Specifically, the gap between how AI coding models perform on standard intelligence benchmarks versus how they perform when you hand them a real production task and say: build me this.
The short version: the gap is enormous. Larger than I expected. And the models most affected by it are not the ones you'd predict.
Why I Ran This
Every week I get asked some version of the same question from founders, engineering leads, and enterprise teams: which AI coding tool should we be using?
The honest answer is that the standard benchmarks — HumanEval, SWE-bench, the various leaderboards — are not useless, but they're measuring something adjacent to what most teams actually need. They're measuring a model's ability to solve isolated algorithmic problems, fill in code completions, or fix discrete bugs in constrained settings.
None of that tells you whether the model can architect a system, maintain coherent state across 20+ interrelated files, write tests that actually pass, or produce something you could hand to a junior engineer and say "run this."
So I ran my own test. And I'm sharing the results here in full.
The Setup
Six models. Five agents each. One task.
The models:
- Claude Opus 4.6 (via Claude Code CLI)
- GLM 5
- Kimi 2.5
- Codex 5.3 High (via Codex)
- Nvidia Nemotron 3
- GPT OSS 120B
Each model was given the same detailed specification and the same instructions: build a full-stack inventory management system for a small import/wholesale business. Not a toy. Not a demo. A production-grade application.
Every team received identical instructions. No model was fine-tuned for this task. No cheating. No head starts.
The full task specification, grading rubrics, agent prompt templates, and all grading reports are published at: github.com/CommanderCrowCode/ai-agent-coding-benchmark
The Task: What "Real Work" Actually Means
The spec was deliberately comprehensive. If you're going to claim a model can "code," this is the kind of thing it needs to be able to build.
The database layer: 20+ interconnected tables. Users with bcrypt-hashed passwords and TOTP-based MFA. Suppliers with contacts. Products with price history. Purchase orders with a 10-stage status workflow. Shipments with milestone tracking. Payments with Wise API integration. Inventory with stock movement ledgers. Sales by platform (Shopee, Lazada, Direct). Background planning tables for seasonality and holidays.
The backend: FastAPI with SQLAlchemy ORM. JWT authentication (HS256, 15-minute access tokens, 7-day refresh). Full CRUD across all entities. An inventory router that handles atomic bulk operations — receive a shipment, record a sale, adjust stock — with pre-validation before any mutation. A background scheduler running hourly stock checks. An audit log that captures every mutation with old and new values, excluding sensitive fields.
The security layer: bcrypt work factor 12. Rate limiting — 100 req/min global, 5 req/min on auth endpoints. Input sanitization with bleach. Fernet encryption for sensitive fields. CORS whitelist. Security headers middleware.
The frontend: Next.js 14 with React 18 and TailwindCSS. A dashboard with KPI cards, order pipeline, inventory health. Loading states, error handling, responsive layout.
The infrastructure: Docker Compose with three services — frontend, backend, nginx reverse proxy. SSL termination. Custom bridge network. Health checks.
The test suite: 117+ pytest tests across 8 test files, covering products, orders, payments, inventory (22 tests alone), suppliers, auth, audit logging, and the inventory monitor service. In-memory SQLite for test isolation. All tests must pass.
This is not a coding challenge. This is a small but complete product.
Two Ways to Score
I evaluated each output on two independent rubrics to reduce the chance of gaming either one.
The relative rubric scores each of the 20 features from 0–10, weighted by business criticality. The inventory router (15% weight) matters more than the email utility (3% weight). Weighted average produces a score out of 10.
The absolute rubric asks a simpler, harsher question: does this actually work? Eight categories, 200 points total. "Does It Run?" (30 pts). "Test Suite" (35 pts). "API Endpoints" (50 pts). "Business Logic" (25 pts). "Security" (20 pts). "Audit Trail" (10 pts). "Frontend" (10 pts). "Schema Completeness" (20 pts).
The absolute rubric is unforgiving. Code that exists but doesn't function scores zero on the relevant category.
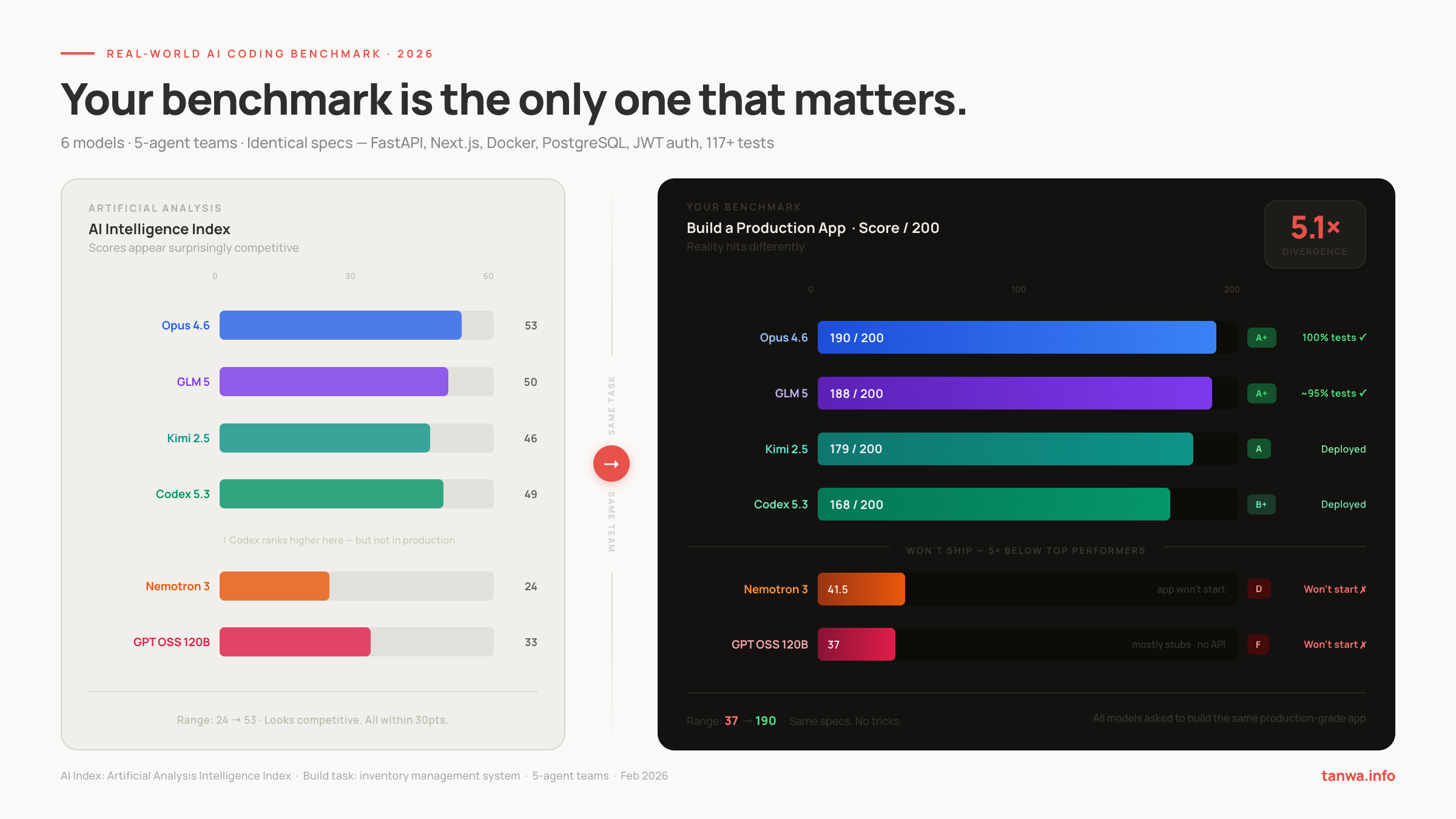
The Results
S Tier: Two Models, One Point Apart
Claude Opus 4.6 — 190/200 absolute · 9.51/10 relative
Every API endpoint functional. Every one of the 117 tests passes at 100%. Business logic complete: atomic bulk operations work correctly, PO status workflow validates forward-only transitions, inventory calculations are accurate. The frontend dashboard loads and displays correctly. Audit logging captures every mutation with full old/new value diffing, sensitive fields excluded.
The weaknesses are real but narrow: no auth rate limiting (the spec calls for 5 req/min on auth endpoints), file-based SQLite for tests rather than in-memory, no SSL configuration in Docker. These are gaps in a few percentage points of the spec, not structural failures.
What it actually feels like to review: a system a senior engineer produced on a good day. Coherent. Tested. Deployable.
GLM 5 — 188/200 absolute · 9.52/10 relative
GLM actually scores higher on the relative rubric — 9.52 vs 9.51. It wrote 140 tests, the most of any model, and used in-memory SQLite for faster test execution (the "right" approach). The infrastructure is more complete: SSL configuration present in Docker, auth rate limiting implemented, full nginx setup.
The weaknesses: some test failures are likely present (the ~95% pass rate versus Claude's 100%). A PO number generation bug. Dependencies listed in pyproject.toml (Fernet, bleach) that aren't actually used in the code. No graceful scheduler shutdown.
What it feels like to review: slightly more ambitious than Claude's output, slightly rougher around the edges. Both are genuinely shippable. Choosing between them comes down to whether you trust test coverage (GLM wins) or test reliability (Claude wins).
These two are separated by two absolute points and 0.01 on the relative score. For practical purposes, they're a tie.
A Tier: The Strong Second
Kimi 2.5 — 179/200 absolute · 8.76/10 relative
Kimi's output surprised me. The purchase order workflow is complete and correct. The inventory router handles all the edge cases. The frontend dashboard is pixel-perfect — full marks on that category. Rich seed data in the init script. API endpoints: 49 out of 50 possible points.
The gaps: the test suite has stubs rather than fully implemented tests (29/35 on that category). Security scoring lower (13.5/20). Background tasks incomplete.
What it feels like to review: a very solid product with a testing gap. If your team writes tests separately or has a QA process, this output is highly usable. If tests-as-documentation matter to you, you'll need to fill gaps.
Codex 5.3 High — 168/200 absolute · 7.84/10 relative
Codex is competent across the board. Database schema complete. Auth working. Good audit trail implementation (9.2/10 on that feature — actually higher than Opus). The frontend scores 10/10 on the absolute rubric.
But it shows meaningful gaps in several areas: the frontend received only 6.6/10 on the relative rubric (suggesting the implementation is functional but not complete per spec). Background tasks scored 7.8. Email utility 7.9. The security posture is reasonable but Fernet encryption isn't implemented.
What it feels like to review: a solid B+ effort. Deployable, but you'd want a code review session before treating it as production-ready.
The Floor: A 5× Drop
Here is where the story gets interesting.
Nemotron 3 — 41.5/200 absolute · 4.26/10 relative
GPT OSS 120B — 37/200 absolute · 3.36/10 relative
Both of these applications fail to start.
Let me be precise about what that means. The code exists. It's not empty files. GPT OSS 120B has a database schema (though it's mostly empty), some route stubs, and a frontend that's partially implemented. Nemotron 3 has a more complete-looking schema (15/20 on schema completeness) and a reasonably capable frontend (7.5/10).
But neither application can be started and used. The APIs return nothing meaningful. The tests — where they exist — crash on import. Nemotron wrote zero passing tests. OSS wrote zero passing tests.
The gap between Codex 5.3 (168 points) and Nemotron 3 (41.5 points) is 126.5 points. Between the best and worst performers: 153 points. On a 200-point scale, that's not a marginal difference. That's a different product category.
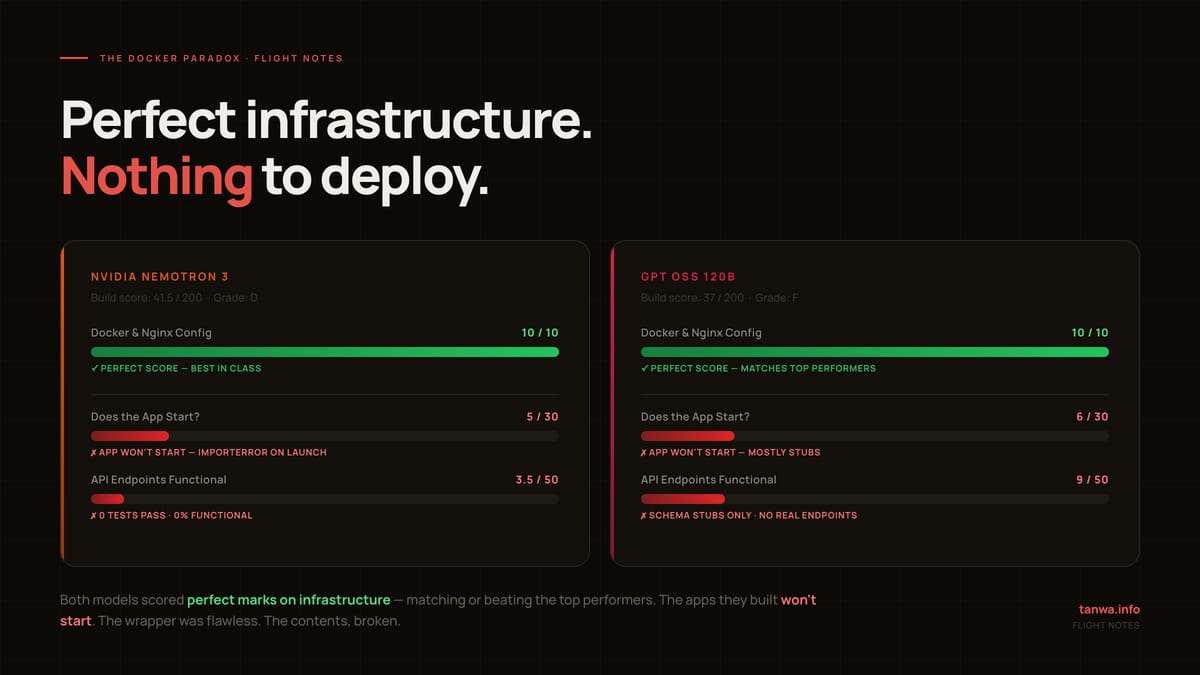
The Docker Paradox
The most counterintuitive finding in this entire dataset deserves its own section.
Both Nemotron 3 and GPT OSS 120B received perfect scores on Docker/Nginx configuration — 10/10 on that feature, matching GLM's infrastructure score and exceeding Claude's (8/10).
Read that again: the two models whose applications do not run wrote the best Docker configurations in the test.
This is not an accident. It reveals something important about how these models work. They have learned, very well, how to produce plausible-looking infrastructure artifacts. A docker-compose.yml with proper service definitions, health checks, resource limits, and network configurations is a pattern. It can be reproduced correctly from training data without the model having any coherent understanding of what it's actually deploying.
The Docker file looks right. The application it points to doesn't work. The wrapper is perfect. The contents are broken.
I've seen this pattern in venture diligence: the deck is excellent. The product doesn't exist yet in any meaningful form. The signals that look most legible — the artifacts that are most pattern-matchable — are often the least informative about the underlying capability.
The Benchmark Reversal
There's a second finding that should give benchmark-watchers pause.
On the Artificial Analysis Intelligence Index — a reputable, widely-cited standard benchmark — Codex 5.3 scores 49, Kimi 2.5 scores 46. Codex is ranked above Kimi. By this measure, Codex is the better model.
In my real-world test: Kimi scores 179/200, Codex scores 168/200. Kimi outperforms Codex by 11 points.
The benchmark got the relative ordering wrong between these two models — not just the absolute scores. This is a meaningful finding. It suggests that the skills being measured by standard intelligence benchmarks and the skills required to architect and ship a real system are not perfectly correlated. They're related, but they're not the same thing.
I want to be careful not to overclaim here. This is one task, one scoring methodology, one set of judges. A different task might flip the result. But the direction of the finding aligns with what I've seen in practice: models that score well on pattern-completion benchmarks don't always translate that into coherent multi-file system design.
What the Numbers Miss
Standard benchmarks measure something real. The Artificial Analysis Intelligence Index aggregates performance across dozens of evaluations — it's not noise. The models at the top of that index (Opus 4.6 at 53, GLM at 50) also top my real-world test. There's signal there.
But the spread is what benchmarks understate. On the AI Intelligence Index, the range across my six models is 24 to 53 — a 2.2× ratio from bottom to top. On my real-world test: 37 to 190 — a 5.1× ratio.
The floor is lower than benchmarks suggest. And the ceiling for the models that can actually execute is higher in practice (because the benchmark measures average performance, not "sustained complex task" performance).
The models that fail in production fail because of compounding. A single feature implemented incorrectly is recoverable. But when the auth layer has a subtle bug, and the database schema is slightly off, and the inventory logic makes an incorrect assumption — and these interact — the whole system can fail to start without any single component being obviously broken. Benchmark tasks are too small to surface compounding failures. Real tasks aren't.
Three Things This Changes For Me
1. The security category is the most interesting divergence.
None of the models scored above 83% on security in my relative rubric. Opus 4.6 — arguably the best overall performer — scored 65% on security in the capability assessment. GLM scored highest at 83%. This is a category where all models show meaningful gaps, and it's the category where gaps matter most in production. Teams using AI to build systems should have a specific security review process regardless of which model they use.
2. Tests are the best proxy for "will this actually work."
The models that shipped working systems wrote working tests. The models that produced non-functional applications wrote no tests, or wrote tests that crash on import. This isn't coincidental: writing a test suite that passes requires a model to have a coherent, internally consistent understanding of the system it built. Tests are a forcing function for correctness. If you're using AI-generated code and you're not insisting on a passing test suite as a deliverable, you're flying blind.
3. The cost story is more complicated than it looks.
Nemotron 3 and GPT OSS 120B cost a fraction of Opus 4.6 to run per token. But if the output doesn't start, the cost isn't lower — it's infinite, because you also have the cost of the engineer who has to figure out why it doesn't work, debug it, and either fix it or redo it. The relevant cost metric isn't cost-per-token. It's cost-per-working-output. By that metric, the models that actually ship may be cheaper at any price point.
How to Run Your Own Version
The most important takeaway is not "use model X" — it's "run your own test."
The models that win my benchmark may not win yours. Different domains, different system types, different tooling contexts will surface different capabilities. My task was a specific kind of CRUD-heavy, multi-entity business application with a strong testing requirement. A model that excels at this may be mediocre at data pipelines, or ML infrastructure, or embedded systems code.
The methodology is simple. I've published everything you need to run a version of this yourself — the task specification, both grading rubrics, the 5-agent prompt templates, and all grading reports — at github.com/CommanderCrowCode/ai-agent-coding-benchmark.
1. Pick a task you actually need done. Not a toy. Something representative of your real work. A service you need to build, a migration you need to write, an API you need to implement. Use the INSTRUCTIONS.md in the repo as a template for how to structure the specification.
2. Write acceptance criteria before you run. Define what "works" means before you see the output. Otherwise you'll unconsciously adjust your bar based on what the model produced. The two grading rubrics in the repo (GRADING_RUBRIC.md and GRADING_RUBRIC_ABSOLUTE.md) show how I structured this — adapt them to your domain.
3. Score on function, not appearance. Does it run? Do the tests pass? Does the business logic produce correct results? A beautiful README doesn't score points.
4. Run at least two or three models. You need a baseline to understand what "good" looks like on your task, because you have no prior reference point. The agent prompt templates in agent_prompts/ are framework-agnostic — adapt them to whatever agentic system you're using.
5. Repeat periodically. These models are updated frequently. A result from six months ago may not reflect current capability. The competitive landscape is moving fast enough that re-running a benchmark quarterly is worth the time.
The Uncomfortable Implication
The AI intelligence benchmarks that get the most attention — the ones that drive procurement decisions, vendor selection, and engineering strategy — are measuring something real but incomplete. They're optimized for visibility and comparability, not for the question teams actually need answered: will this help me ship?
The gap between "scores well on benchmarks" and "builds working software" is not a bug in the benchmarks. It's an inherent limitation of what can be measured at scale, cheaply, in a way that's resistant to gaming. Isolated coding tasks are verifiable. System-level coherence is harder to test.
But that gap is your opportunity. Teams that run their own real-world evaluations before committing to a tool — rather than relying on published leaderboards — will consistently outperform teams that don't. Not because the benchmarks are wrong, but because your benchmark is the only one that matters for your work.
The models at the top of my test are genuinely impressive. A five-agent team using Claude Opus 4.6 produced a deployable, fully-tested full-stack application — database schema, API layer, frontend, Docker infrastructure, 117 passing tests — from a single spec. That's a real capability shift for small teams.
But that shift only accrues to teams that know how to evaluate it.
This analysis used two independent rubrics across 200 assessment points and 20 feature categories. Task specification: FastAPI + SQLAlchemy backend, Next.js 14 frontend, Docker Compose infrastructure, PostgreSQL schema (20+ tables), JWT + TOTP auth, 117+ tests. All models received identical instructions. February 2026.
Full methodology, rubrics, agent prompts, and grading reports: github.com/CommanderCrowCode/ai-agent-coding-benchmark
If you're evaluating AI coding tools for your team and want to talk through the methodology or results, reach out via tanwa.info.



